
A new database collects individual-level COVID-19 data, such as travel history and when a person first felt sick.Credit: An Yuan/China News Service/Getty
An enormous international database launched today will help epidemiologists to answer burning questions about the coronavirus SARS-CoV-2, such as how rapidly new variants spread among people, whether vaccines protect against them and how long immunity to COVID-19 lasts.
Unlike the global COVID-19 dashboard maintained by Johns Hopkins University in Baltimore, Maryland, and other popular trackers that list overall COVID-19 infections and deaths, the new repository at the data science initiative called Global.health collects an unprecedented amount of anonymized information about individual cases in one place. For each individual, the database includes up to 40 associated variables, such as the date when they first had COVID-19 symptoms, the date they received a positive test and their travel history.
Individual-level data like these provide the clues that epidemiologists need to determine how diseases are spreading, says Caitlin Rivers, an epidemiologist at Johns Hopkins , who is part of the project. “By the time we understand the gravity of an outbreak, it’s often too late,” she says. “Data can close that loop and make the process faster.”
Researchers hope the database will help them to monitor coronavirus variants and vaccines in the months to come, and provide a template for tracking real-time data in future epidemics.
The repository was created by 21 researchers at 7 academic institutions in the United States and Europe, with technical and financial support from Google and the Rockefeller Foundation. So far, the team has collected information from 24 million cases across some 150 countries.
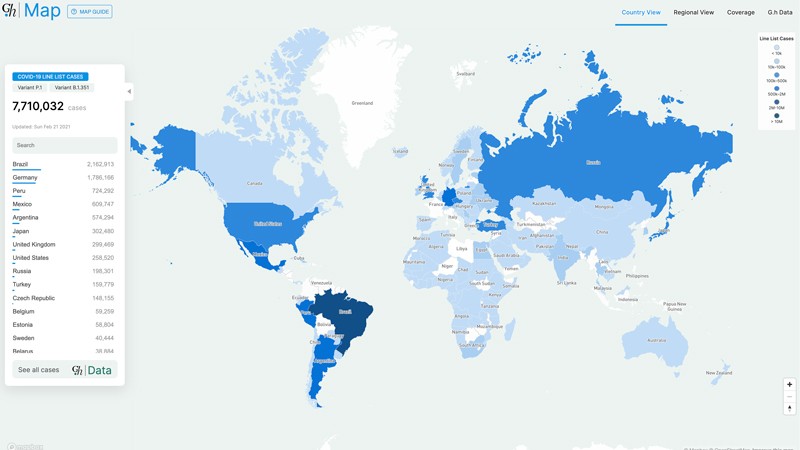
At launch, the Global.health website offered data visualizations such as this map, which shows the distribution of a portion of the COVID-19 infections in the repository. Users can click on 'variant' buttons to see where these particular viruses have been reported. Dark blue indicates more cases in the repository, and light blue indicates fewer cases.Credit: Global.health
Rivers adds that a database like this would have been useful early in the SARS-CoV-2 outbreak. Epidemiologists might have been able to verify that the coronavirus was frequently spreading from person to person in China even before the World Health Organization confirmed it on 23 January last year — possibly helping to curb the pandemic sooner.
Several scientists say the advent of a comprehensive, international and publicly available repository will provide fuel for research on several fronts. “This is really good, and needs to be done,” says Robert Garry, a virologist at Tulane University in New Orleans, Louisiana. “Nothing like this exists because it’s so hard to do.”
A collective effort
Whenever an outbreak occurs, epidemiologists collect and organize bits of information drawn from newspaper articles and health agencies into homemade spreadsheets. Details on a person’s symptoms, their age, how they might have been infected and so forth help researchers to determine a disease’s cause, its contagiousness and its mortality rate.
By mid-January 2020, epidemiologists were doing just this for SARS-CoV-2 — but had not come to a consensus about their findings. Sam Scarpino, an epidemiologist who directs the Emergent Epidemics Lab at Northeastern University in Boston, Massachusetts, tweeted that the evidence didn’t confirm sustained human-to-human transmission. And he remembers Rivers responding to him in a direct message: “She said, ‘Dude, I think you’re wrong.’”
The data were still murky. But another epidemiologist, Moritz Kraemer at the University of Oxford, had created and shared his own Google spreadsheet with the community. Scarpino analysed the numbers, and conceded that Rivers was right.
Soon, dozens of epidemiologists were adding information from cases around the world to that spreadsheet. At the same time, they and others were analysing it. For example, Adam Kucharski, an epidemiologist at the London School of Hygiene & Tropical Medicine, and his colleagues used the data to estimate that there were about ten times as many people in Wuhan, China, with COVID-19 symptoms in January as had been confirmed by health officials, based partly on the number of people who had travelled out of the country and had a confirmed infection1.
After exceeding about 100,000 cases, the original spreadsheet was overloaded. In April, the team got assistance from engineers and product developers at Google and Google.org, the charitable arm of the Silicon Valley company. Together, they wrote computer codes that would automatically upload daily coronavirus data from about 60 governments in a standardized format, codes that delete duplicate entries and an algorithm to merge information being added from around the world into a single cloud-based repository.
Prioritizing privacy
Anyone can register to access up to 8 gigabytes of anonymized data on the latest version of the Global.health database. Half of the 24 million cases collected have data for a dozen variables, and about 10% have more, says Scarpino. For now, the website’s data visualizations are limited to maps displaying data the team has collected. Scarpino notes that infographics haven’t been a focus, because they prioritized standardizing data collection and navigating privacy issues so that people around the world can add to the database. The project’s architects consulted legal and ethical specialists about how to securely handle and share anonymized data about individuals, he says, which are often closely guarded by government agencies, universities and hospitals.
Julien Riou, an epidemiologist at the University of Bern in Switzerland, looks forward to exploring the database. So far, he’s based much of his COVID-19 work on data from a Swiss cohort, but he says a deep, international dataset could provide better answers to fundamental questions, such as the true rate of infection in countries around the world. “More data means we can get closer to the truth,” he says. Other researchers agree, adding that information on a person’s vaccine status or whether they’re infected with a coronavirus variant could help to answer pressing scientific questions about immunity in the months to come.
Kucharski welcomes funds for the project. “A lot of these databases are crowdsourced, but if you just rely on volunteers, it’s often not sustainable,” he says.
Scarpino hopes to eventually expand the COVID-19 database onto an adaptable platform to survey other diseases — especially the next emergent epidemic. But doing this, he says, would require a company, non-profit organization or other venue to carry the project forward — a lesson he learnt from software he worked with previously, which originally tracked health data in Syria, but is now used in more than a dozen countries after being sold to a data company. He says, “This can’t be a flash in the pan.”
"and" - Google News
February 24, 2021 at 04:22PM
https://ift.tt/2ZMfaOE
Massive Google-funded COVID database will track variants and immunity - Nature.com
"and" - Google News
https://ift.tt/35sHtDV
https://ift.tt/2ycZSIP
And
Bagikan Berita Ini














0 Response to "Massive Google-funded COVID database will track variants and immunity - Nature.com"
Post a Comment