Pure Storage has added greatly increased scale-out for its arrays with clusters in availability zones, and added cloud-like storage resource consumption and management, as well as automated database deployment services for containerised apps.
It lifted the veil today on Pure Fusion, which it calls a self-service, autonomous, SaaS management plane; enhanced Pure1 operational management; and Portworx Data Services (PDS). Fusion is a federation capability for all Pure devices — on- and off-premises — with a cloud-like hyperscaler consumption model. PDS, meanwhile, brings the ability to deploy databases on demand in a Kubernetes cluster.
Pure’s chief product officer, Ajay Singh, said: “Customers want a new agile storage experience that is fully automated, self-service, and pay-as-you-go. Pure Fusion breaks down the traditional barriers of enterprise storage to deliver true storage-as-code and much faster time to innovation.”
Murli Thirumale, VP and GM, Cloud Native Business Unit, Pure Storage, said Portworx Data Services showed the firm had made progress in helping customers to deploy stateful applications on Kubernetes: “Now we don’t just give IT teams the tools needed to run data services in production, we are providing an as-a-service experience for the data services themselves so our customers can focus on innovation, not operations.”
Pure provides all-flash storage resources for both traditional applications and for containerised applications. Drilling down into the conceptual aspect, traditional apps running on-premises are provisioned using abstractions such as LUNs, and arrays with defined capacities, whereas public cloud provisioning is on the basis of capacity, service classes, protection levels and near-infinite scale-out. In the containerised world, Kubernetes facilitates storage provisioning but also brings a whole new dimension of complexity with application deployment and monitoring. It can be used to automate both storage provisioning and application deployment.
The idea is for the Pure infrastructure to combine to form greater resource pools. For traditional environments that infrastructure is presented as cloud-like, with service classes and in-built workload placement and balancing. For cloud-native — for example Kubernetes-based — shops, their ability to deploy databases on the Pure infrastructure is now automated, as is their ongoing (“day 2”, as the kids say) management.
Pure Fusion
Pure International CTO Alex McMullan told B&F: “Fusion … is a SaaS layer to federate Pure arrays together into a software-defined and multi-tenant private cloud.”
He added: “This is Pure’s first major journey into active management. Pure1 today is a monitoring and read-only portal. The change that comes with Fusion is that we’ll be managing Pure devices actively from the cloud layer, from the SaaS layer, and that’s a huge thing that has been planned, discussed, syndicated with customers for many years.”
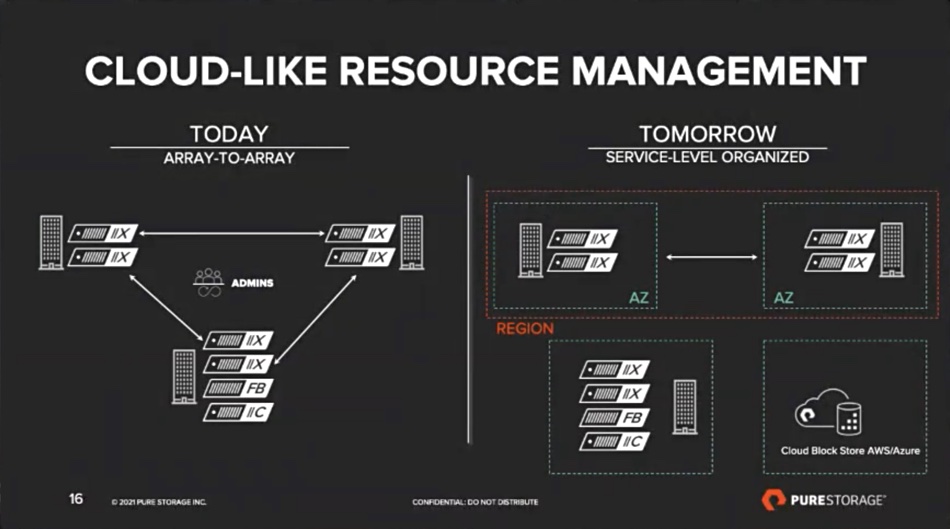
Pure Fusion provides availability zones and regions across clusters of Pure arrays, including Cloud Block Store, with everything organised by service level. Storage admins can define a catalogue of storage classes with different access types (block, object, file), performance and protection and cost profiles. Users can then self-select the class they want with a UI click, or software API call and a “Pure1 layer for Fusion to automatically implement those changes behind the scenes, without anyone knowing.”
In theory, customers will be able to provision and deploy storage volumes faster, from common tools developers use today like Terraform and Ansible, with an API-first interface. Their storage will also have higher availability through the use of availability zones.
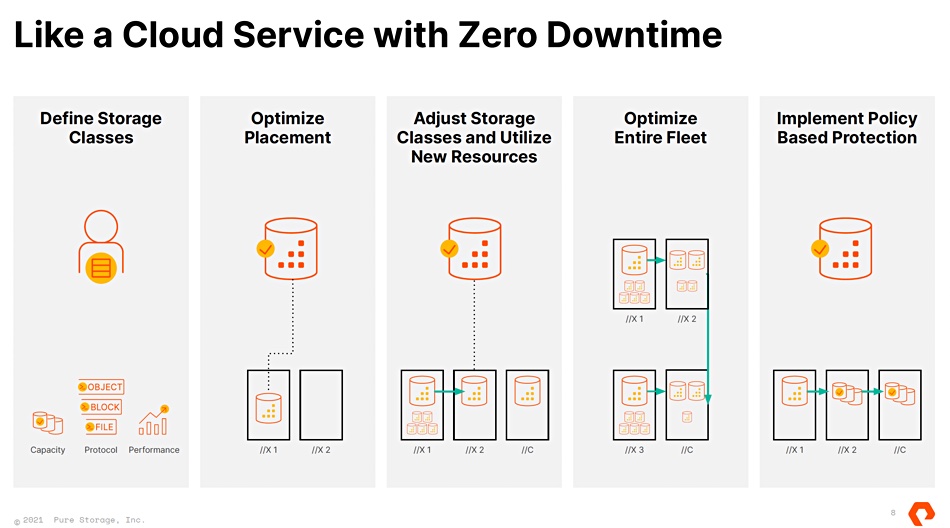
Suppose there is an array problem? McMullan said that, with Pure1’s access to array telemetry data, the firm and Fusion can “work between themselves to work out the best place for a data set to be and to move it there with Active Cluster. … it’s all completely transparent to the user, the storage administrator, the DBA and, of course, to the end application as well.”
McMullan added: “Each part of the federation of pools of capacity is carved into tenant spaces. For each of those tenant spaces there’s an overall administrator, allowing different storage classes to be defined per tenant space, each with its own separate administrator. … Each tenant space can call out into any Availability Zone, any region or more than one region with protection policies to be able to run their business in the way that they see is optimal.”
Pure Fusion scaling will integrate first with FlashArray//X, FlashArray//C, and Pure Cloud Block Store, and has future integrations planned with FlashBlade and Portworx.
Portworx Data Services
Cloud native development features rapid code iterations and complex database deployments, which means DevOps staff end up doing a lot of Ops work along with the Dev. Portworx Data Services is aimed at reducing their Ops-type workload by automating database deployments. It’s built on the Portworx Enterprise product.
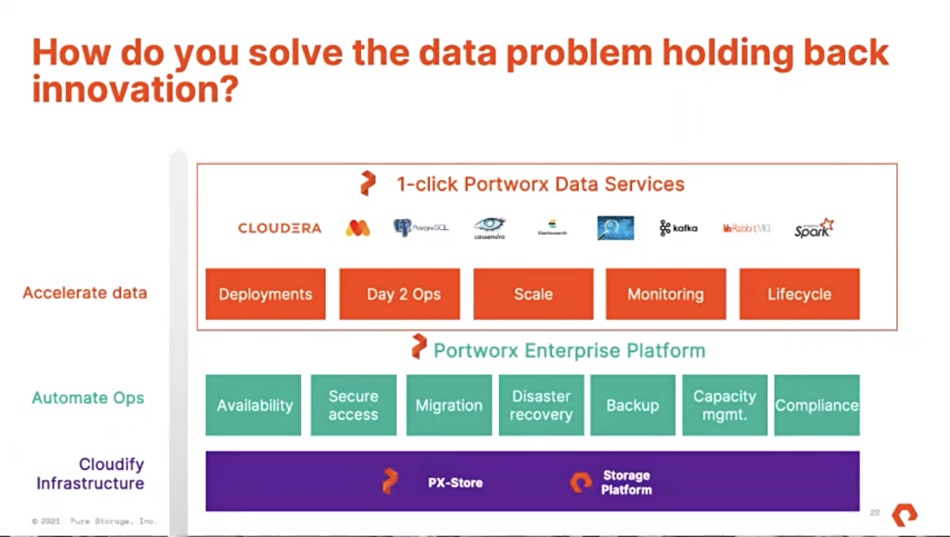
Users select a database type — such as Cassandra, Couchbase, ElasticSearch, Kafka, or MongoDB — its name and size, and it is then downloaded from the container registry, installed on a cluster, and brought up by the Kubernetes operator. The user then gets a connection string back so they can use the database.

The data protection is taken care of by Portworx. The product is database-as-a-service, McMullan said: “No more ServiceNow tickets, no more help desk tickets, no more calling help desks. You click and you go; you deploy as you would do in the public cloud.”
A range of SQL and NoSQL databases will be supported. According to McMullan: “We’re going to start with a couple of the obvious ones in terms of Cassandra, Kafka. Rabbit MQ, I think, is one of the others, and that list will get longer as we approach GA.”
He said: “Portworx Data Services is able to maintain, expand capacity, monitor, feedback, and take repetitive actions, if and when there’s a database problem.
“It won’t do DBA-based tasks in terms of table management, the traditional things. That still goes via the normal service, but the actual capability of bringing the database up inside the application for the developer, the DBA, the data scientists to consume the endpoint, is all taken care of automatically.”
He emphasised that “the ability to repeatedly deploy and manage and maintain and protect containerised applications is something that nobody else can offer, talk about or even do right now, so this is an industry first for us.”
Availability
Both Pure Fusion and Portworx Data Services are in an Early Access Programs. Fusion will be in preview by the end of this year, with general availability to come in the first half of 2022. Portworx Data Services should be generally available in early 2022.
"with" - Google News
September 28, 2021 at 08:00PM
https://ift.tt/3m5CjGA
Pure scales out with availability zones, automated and active storage management, and database deployment – Blocks and Files - Blocks and Files
"with" - Google News
https://ift.tt/3d5QSDO
https://ift.tt/2ycZSIP
Bagikan Berita Ini














0 Response to "Pure scales out with availability zones, automated and active storage management, and database deployment – Blocks and Files - Blocks and Files"
Post a Comment